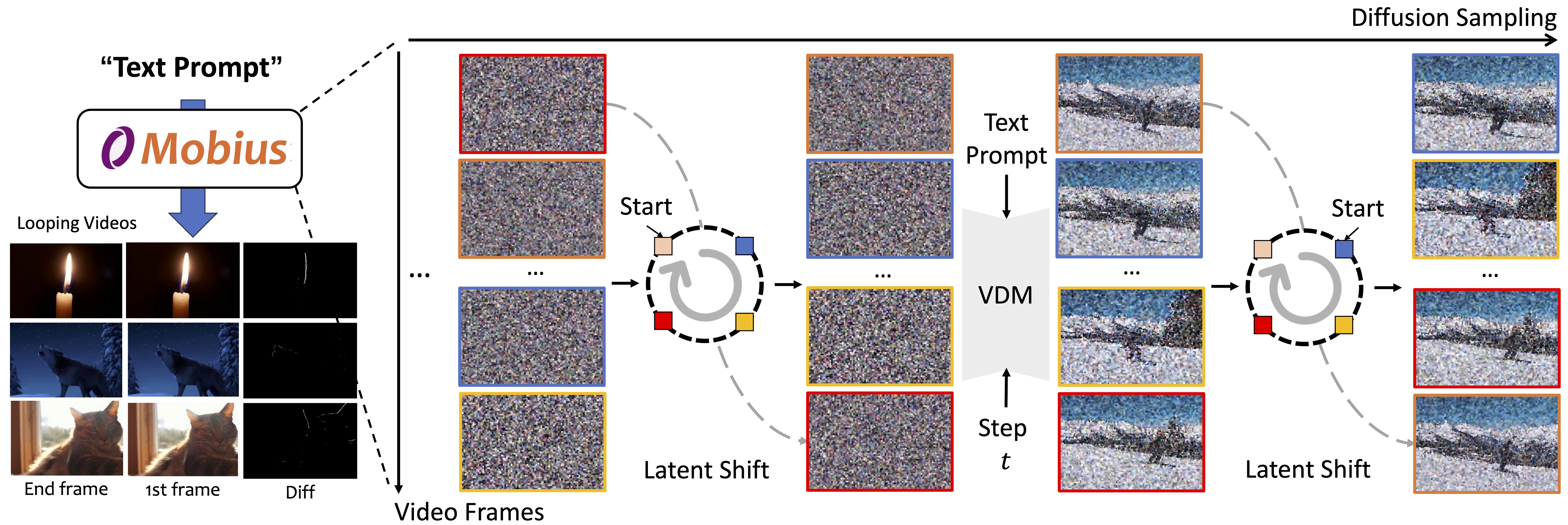
We present Mobius, a novel method to generate seamlessly looping videos from text descriptions directly without any user annotations, thereby creating new visual materials for the multi-media presentation. Our method repurposes the pre-trained video latent diffusion model for generating looping videos from text prompts without any training. During inference, we first construct a latent cycle by connecting the starting and ending noise of the videos. Given that the temporal consistency can be maintained by the context of the video diffusion model, we perform multi-frame latent denoising by gradually shifting the first-frame latent to the end in each step. As a result, the denoising context varies in each step while maintaining consistency throughout the inference process. Taking 4 latent toys pre-trained Video Diffusion Models(VDM) as an example, we build a latent cycle and shift the start point in each denoising step in inference for text-guided looping video generation. Notice that, the shifting is conducted in the latent space, we emit the latent encoder and decoder for easy understanding.
Our method is based on the pre-trained open-source latent video diffusion model, CogVideoX-5B. Since there is no previous work for open-domain looping video generation from a text description, we majorly compare two generative interpolation methods and one method from the community. Specifically, we comapre with Svd-Interp., CogX-Interp., Latent Mix, and dirct generation of CogvideoX.
CogVideoX
Svd-Interp.
CogX-Interp.
Latent-Mix
Ours
A rugged man in a sleek, insulated black ski jacket and matching ski pants glides effortlessly down a pristine, powdery white slope, his movements fluid and graceful. His goggles reflect the brilliant sunlight, and his breath forms visible puffs in the crisp mountain air. The backdrop is a breathtaking panorama of snow-capped peaks and towering pine trees, their branches lightly dusted with snow. As he navigates the slopes, his ski poles rhythmically punctuate the snow, leaving a trail of precise, parallel lines. The scene transitions to a close-up of his focused expression, the wind tousling his hair, capturing the exhilaration and freedom of the sport.
A young female activist stands tall, holding a flag high above her head with determination in her eyes. The flag flutters in the breeze, its bold colors contrasting with the backdrop of a city street or public space. Her posture is confident, embodying strength and resolve as she becomes a symbol of the cause she represents. The surrounding environment captures the energy and passion of her movement.
A bicycle glides smoothly down a tree-lined lane, its wheels softly humming on the asphalt. The stationary camera captures the silhouette against the sun-dappled road. The scene loops as the bike exits the frame and re-enters on the other side.
Our method can be easily extended to the generation of longer looping videos.
Frames 50
Frames 100
Frames 150
A single candle flickers in the center of a dimly lit room, its flame casting soft, dancing shadows on the walls. The wax slowly melts, pooling at the base as the light flickers intermittently. The air remains still, creating a calming, rhythmic loop that feels both timeless and peaceful.
Brilliant fireworks explode in the night sky, scattering trails of red, blue, and gold. The camera zooms in on a particularly vibrant burst, revealing intricate streaks of light before pulling back to show the whole scene. The loop continues with another explosion lighting the darkness.
We show that our method supports longer video inference beyond the training context by a non-cycle latent displacement. We utilize the same RoPE interpolation as we introduced before to correct the position of the latent. We compare our method for longer video generation, including Gen-L-Video, FreeNoise, FIFO, DitCtrl and Naïve, which is the method of direct inference generation. The following two lines of the video case are about 100 frames and 240 frames respectively.
Naïve
Gen-L-Video
FreeNoise
FIFO
DitCtrl
Ours
A young female activist stands tall, holding a flag high above her head with determination in her eyes. The flag flutters in the breeze, its bold colors contrasting with the backdrop of a city street or public space. Her posture is confident, embodying strength and resolve as she becomes a symbol of the cause she represents. The surrounding environment captures the energy and passion of her movement.
A seagull, its white and grey feathers ruffled by the wind, walks along the shore, its sharp beak occasionally probing the sand for food. The rhythmic sound of the ocean waves crashing against the shore fills the air, and the seagull’s feet leave soft tracks in the wet sand as it moves. In the distance, the sun sets, casting a golden glow across the water and illuminating the bird’s graceful movements. A few other seagulls are seen flying overhead, their calls adding to the peaceful coastal ambiance.
We have given the examples to validate the effectiveness of the proposed frame-invariance latent decoding, different latent skip and the RoPE interpolation. Regarding frame-invariant latent decoding and the RoPE interpolation, note the difference between the first frame of the videos.
CogVideoX
w/o frame-invariance latent decoding
Ours
A woman in a flowing, white sundress and sunglasses, her hair tousled by the sea breeze, runs along a golden sandy beach as the late afternoon sun casts long shadows. The ocean's waves crash rhythmically in the background, and seagulls cry overhead. Her determined stride contrasts with the serene sunset hues painting the sky, capturing a moment of freedom and escape as the day transitions to evening. The scene embodies the perfect blend of tranquility and vitality, with the woman's silhouette framed against the fading light.
Skip = 0
Skip = 1
Skip = 6
A fox moves through the forest, its body sleek and agile as it glides over the ground. With each step, the watercolor brush captures the graceful movement of its paws on the soft forest floor, the colors of the trees and leaves blending in the background. The fox pauses, tilting its head to listen, before it leaps forward, its body moving fluidly through the brush, and then it darts off, its form blending with the shifting hues of the forest.
w/o RoPE-interp.
Shifted RoPE-interp.
Fixed RoPE-interp.
A playful black dog, dressed in a bright orange pumpkin costume with black bat wings, stands on a patch of grass under the warm glow of autumn sunlight. Its fluffy tail wags as it prances excitedly, the Halloween costume gently swaying with each movement. Moments later, the dog is seen running in circles, ears flopping with joy, while a soft breeze rustles nearby fallen leaves.
Since our method is a training-free method based on the pre-trained video diffusion model, our motion prior might be influenced by the pre-trained video diffusion model. The generated results might not show a very smooth video in the customized domain.
A woman with a flowing scarf spins slowly in the wind, the fabric trailing behind her in an elegant swirl. Her body moves fluidly, and the soft watercolor strokes capture the motion of her dress and scarf, blending the movement into the wind that carries her. As she spins faster, the fabric billows outward, and the brushstrokes create a whirlwind effect, capturing the softness and grace of her motion.
@article{2025mobius,
author = {Bi, Xiuli and Yuan, Jianfei and Liu, Bo and Zhang, Yong and Cun, Xiaodong and Pen, Chi-Man and Xiao, Bin},
title = {Mobius: Text to Seamless Looping Video Generation via Latent Shift},
booktitle = {arxiv},
year = {2025},
}